들어가며
약 1.3MB 정도 되는 CSV 파일 (약 4000줄) 5천 개를 데이터베이스에 적재하려고 시도하였습니다. OutOfMemory가 발생하였습니다. 1 record 당 1 instance로 List에 담았기 때문입니다. 객체 2,000만 개를 만들고 List에 담아 GC도 되지 않는 코드를 작성해 버린 것입니다.
1) CSV 한 줄 씩 읽고 객체 만들어 List에 add 하기
2) 2000만 길이의 List (이 단계에서 OOM 발생!)
3) 2,000만 길이의 Batch쿼리
4) 한 방에 Insert 시도
Heap GC 상태 확인
PID를 찾는 동안 잠시 대기를 시켜줍니다.

PID가 39205입니다. 35394는 PPID로 인텔리제이입니다.

인텔리제이의 부모는 MAC에서의 1번 프로세스인 launchd 이군요.

jstat 명령어를 돌려줍니다.

아래는 Scanner 입력 대기 중인 상태입니다.

이제 아무 키나 입력하여 프로세스를 진행시키고 heap 및 gc 상태를 관찰합니다.
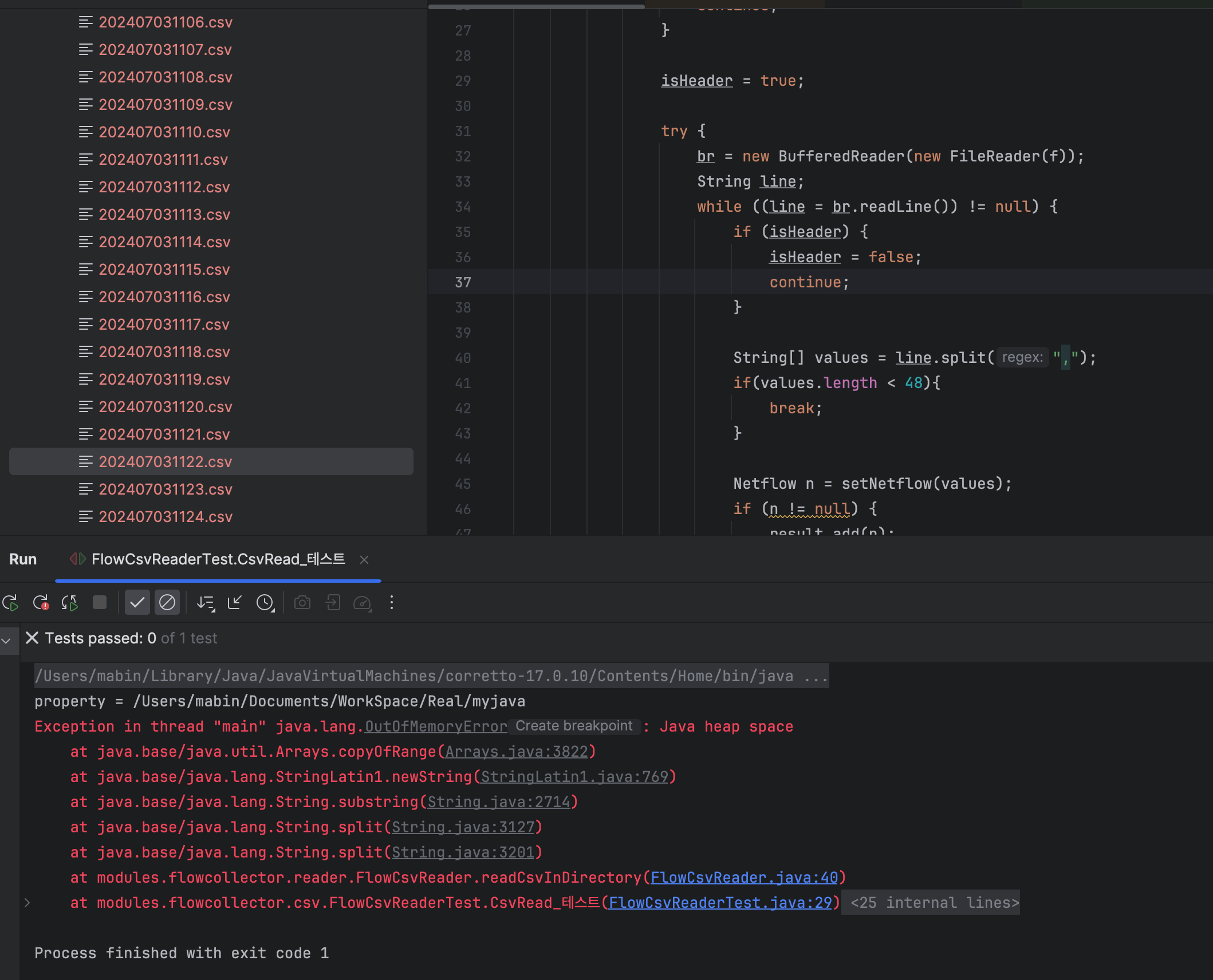
그런데 콘솔 입력이 안됩니다. @Test 실행으로 돌리니까 발생하는 문제로 보여 main메서드로 재시도하였습니다.
다시 확인한 PID는 44981입니다.

대기 중 jstat -gc입니다.

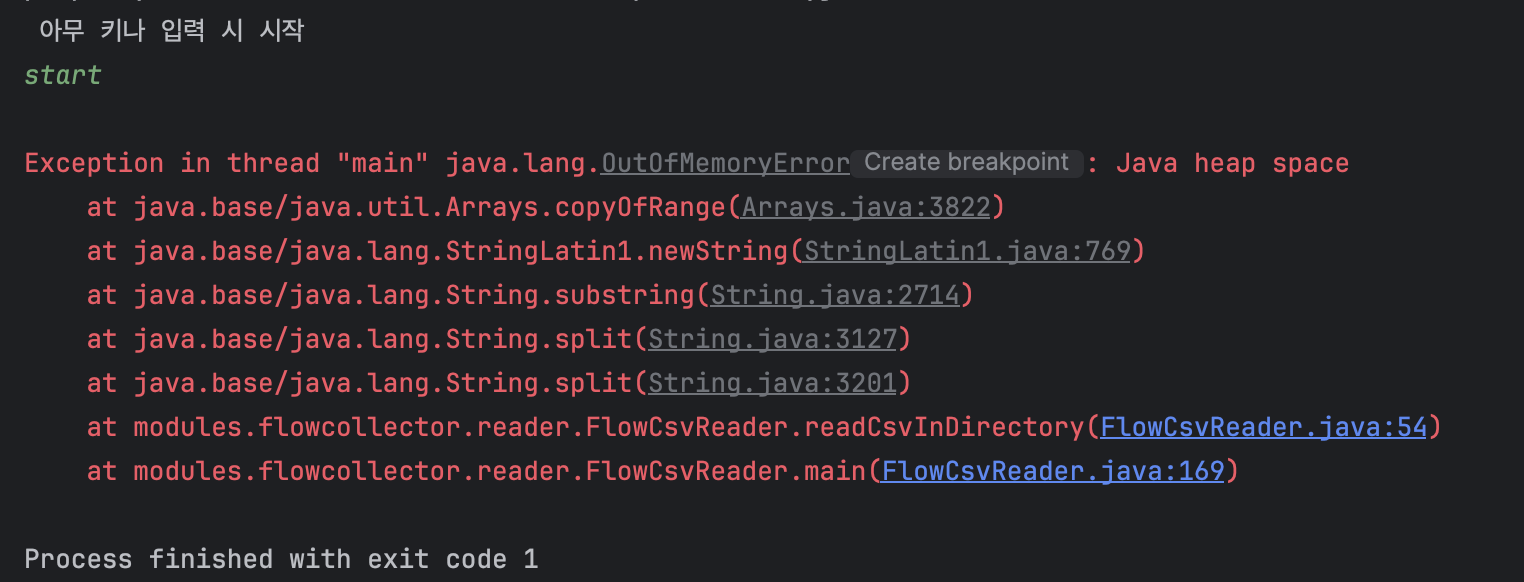
OOM 발생 후 jstat -gc 상태입니다.
해석을 위한 필드값 설명입니다.(man페이지 발췌)
-gc option
Garbage-collected heap statistics.
SeC: Current survivor space 0 capacity (kB).
SIC: Current survivor space 1 capacity (kB).
SOU: Survivor space 0 utilization (kB).
SIU: Survivor space 1 utilization (kB).
EC: Current eden space capacity (kB).
EU: Eden space utilization (kB).
OC: Current old space capacity (kB).
OU: Old space utilization (kB).
MC: Metaspace capacity (kB).
MU: Metacspace utilization (kB).
CCSC: Compressed class space capacity (kB).
CCSU: Compressed class space used (kB).
YGC: Number of young generation garbage collection events.
YGCT: Young generation garbage collection time.
FCC: Number of full GC events.
FGCT: Full garbage collection time.
GCT: Total garbage collection time.
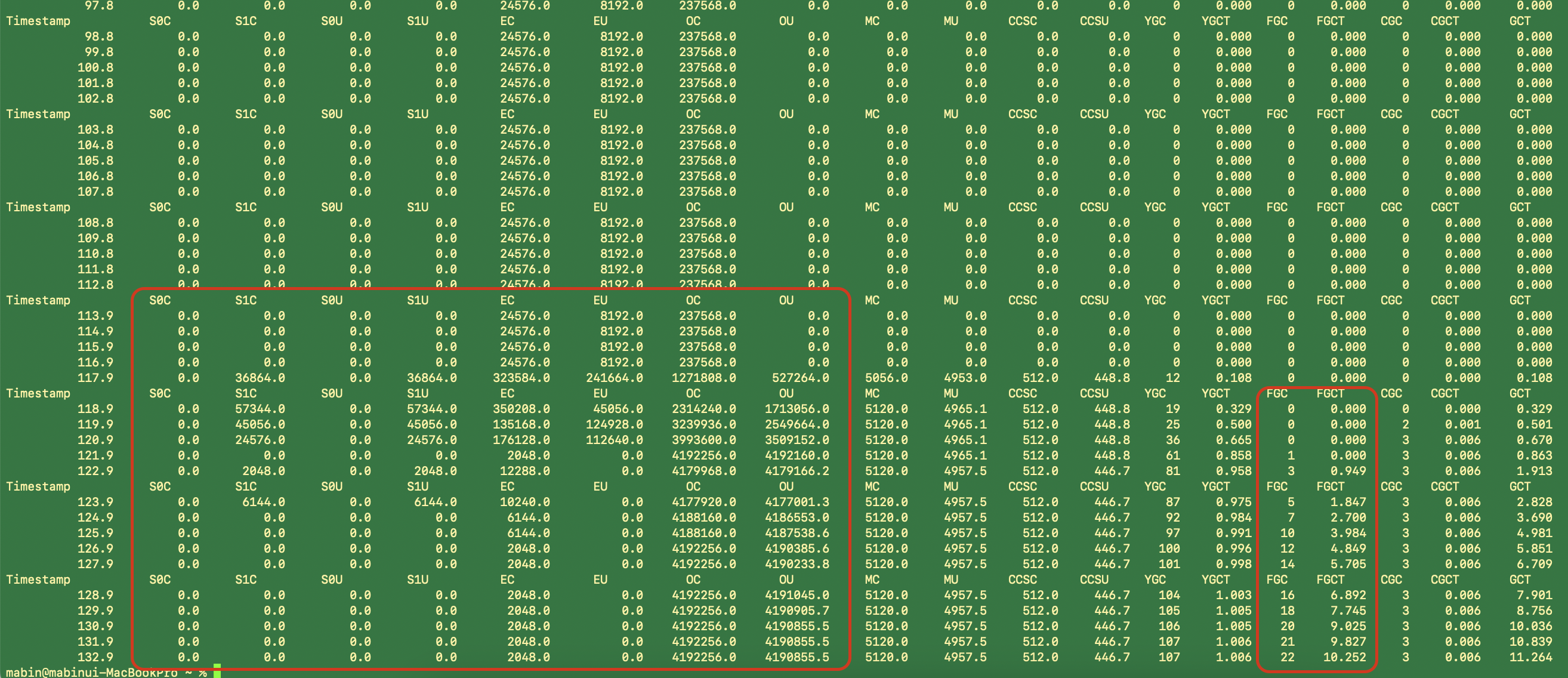
Old 영역 이용량이 Old 영역 Capa에 도달하자 다급하게 Full GC 돌리는 JVM의 모습입니다. 하지만 저의 record 객체들은 List에 의해 참조되고 있기 때문에 Full GC에 당하지 않고 JVM을 끝장내 버렸습니다 여기서 Heap Size가 대략 4GB까지 치솟았습니다. 작업 맥북의 메모리가 16GB인데 대략 메모리의 25%를 사용하였습니다.
메모리가 허용하는 적은 개수의 CSV는 가능합니다. 하지만 대량의 CSV를 처리할 때는 일정 단위로 끊어주어야 할 것 같습니다. Spring Batch에서 말하는 Chunk 단위가 이런 것이 아닐까 싶습니다. (일단은 직접 구현해 보고 Spring Batch를 이용해서도 구현해 보아야겠습니다.)
현재 하고 있는 부분은 아래 구성도에서 빨간색 테두리에 해당합니다.
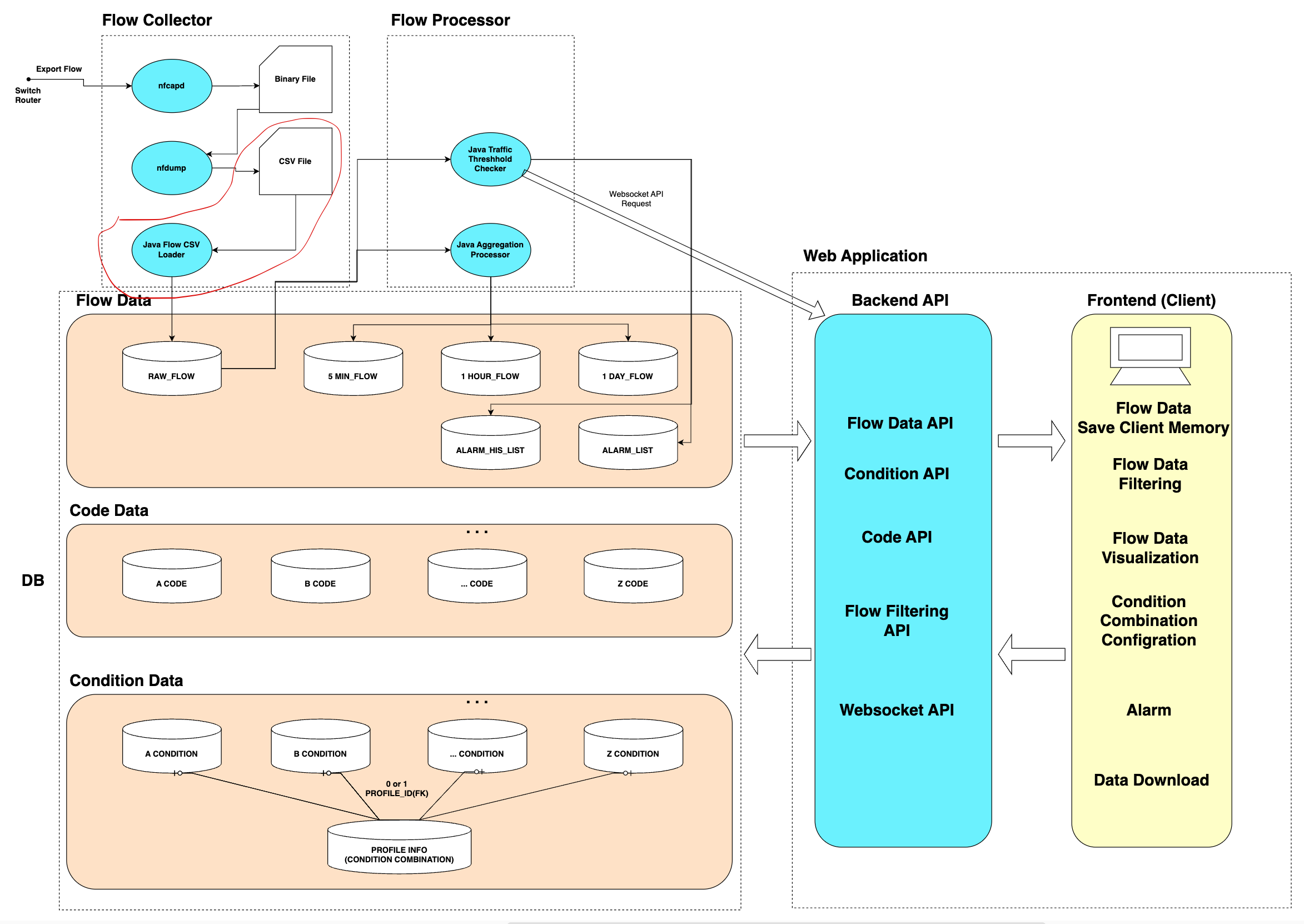
현재는 Flow Binary 파일을 읽어서 1분 단위로 CSV파일을 저장하도록 nfdump를 돌리고 있습니다. 이 주기에 맞춰서 Java 프로세스도 CSV파일을 읽어서 DB에 착착 적재를 해주어야 합니다. 현재는 4000줄의 CSV파일 하나를 AWS 테스트 DB에 Insert 하는데 대략 600ms정도가 소요됩니다. 네트워크 지연도 고려해야겠지만 (가상 면접 사례로 배우는 대규모 시스템 설계 기초에 따르면) 이는 캘리포니아에서 네덜란드까지 4번 왕복하는 지연시간과 비슷합니다.
이 프로젝트에서는 Flow 데이터를 필터링하여 시각화하고, bps 기반 과금 처리를 하는 것이 핵심입니다. 따라서 데이터를 수집하고 DB에 적재하는 부분은 굉장히 중요합니다. 로직은 간단하지만 성능과 안정성이 보장되어야 하는 것입니다. 실제 환경에서 혹시나 있을지 모를 데이터 급증으로 인해 OOM이 발생한다면 트래픽을 측정하지 못한 기간의 과금 누락으로 폭풍이 몰아칠 것입니다.
각설하고, 다시 조치로 돌아가보겠습니다.
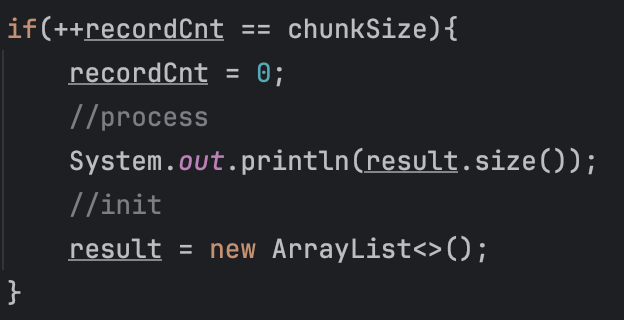
조치에 대한 메인 아이디어는 일정 단위로 끊어주고 처리하고 참조를 끊어서 GC처리하게 하는 것입니다. 간단하게 파라미터로 넘겨받은 chunkSize만큼 끊고 List를 초기화하여 참조를 끊어보았습니다.
아래의 코드를 추가하였습니다.
이번 PID는 49970입니다.

대기 상태의 jstat -gc입니다.

이번에는 OOM이 발생하지 않았습니다.
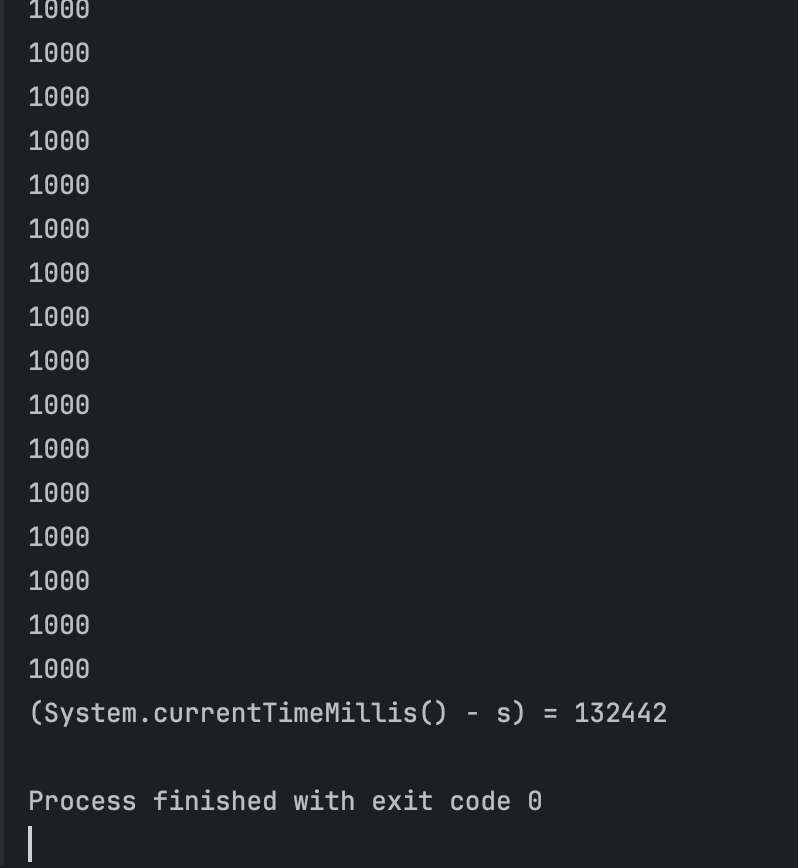
(가동시간은 Scanner 입력 대기 시간이 포함되었습니다.)
프로세스 정상 종료 후 확인한 jstat -gc의 상태입니다.
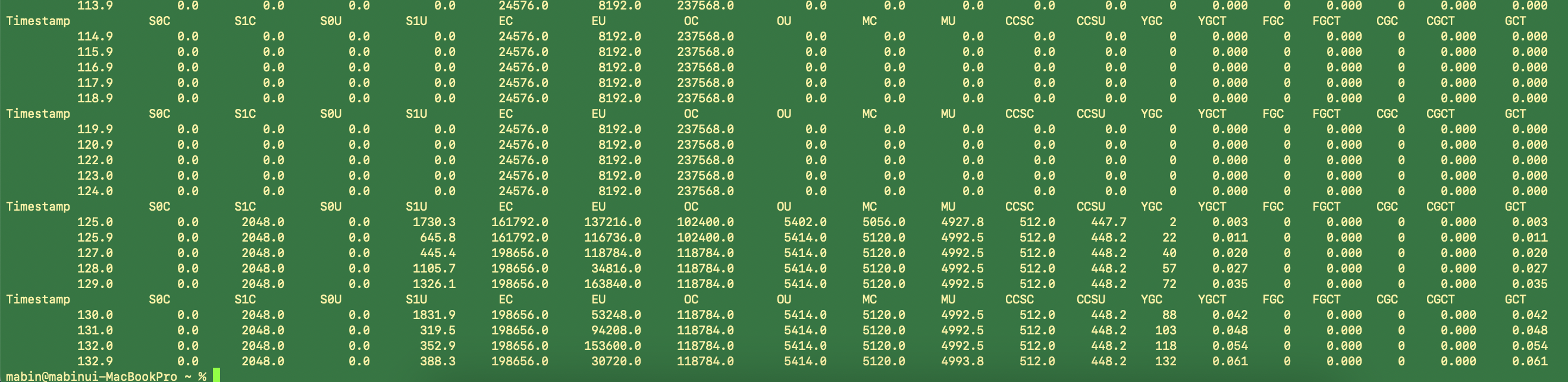
대략, record 객체들이 Young GC 선에서 처리되어 Old 영역까지 넘어가지 않은 것으로 보입니다. Full GC는 발생하지 않았습니다.
결론
- OOM 해결 - 메모리가 허용하는 Chunk 단위 ( Spring Batch의 용어를 따서 )로 나누어 처리하고 처리한 객체는 참조를 끊어 GC 되도록 하여 OOM을 방지하였습니다
- 적절한 설정 필요 - 적절한 Chunk사이즈의 설정이 필요합니다. 사이즈가 작아지면 메모리 관리가 안정적이지만 DB 처리가 많아져 느려질 것이고, 사이즈가 커지면 메모리의 부하가 커질 것입니다.
- 추가 조치 필요 - 각 Chunk단위의 작업을 병렬처리하여 스케줄 사이클 내에 처리할 수 있도록 하여야 합니다.
읽어주셔서 감사합니다. 댓글로 의견 부탁드립니다:)
'개발 > 개발' 카테고리의 다른 글
| [개발관련] 터널링 유지 스크립트 ssh -R (0) | 2024.07.29 |
|---|---|
| [개발관련] ssh 리모트 터널링과 로컬 터널링 (0) | 2024.07.25 |
| [개발관련] @ForceInline 테스트 (0) | 2024.07.03 |
| [개발관련] JAVA_ IPv4 String to Int 변환 (2의 보수, 비트 연산) (0) | 2024.06.22 |
| [개발관련] Docker_ MariaDB Container 만들기 (0) | 2024.06.01 |